Introduction:
Natural Language Processing, or NLP, for short can be explained as the automated manipulation, or processing of language (or natural language, that is, the language which is used by humans) in the form of speech or text, by a computer software.
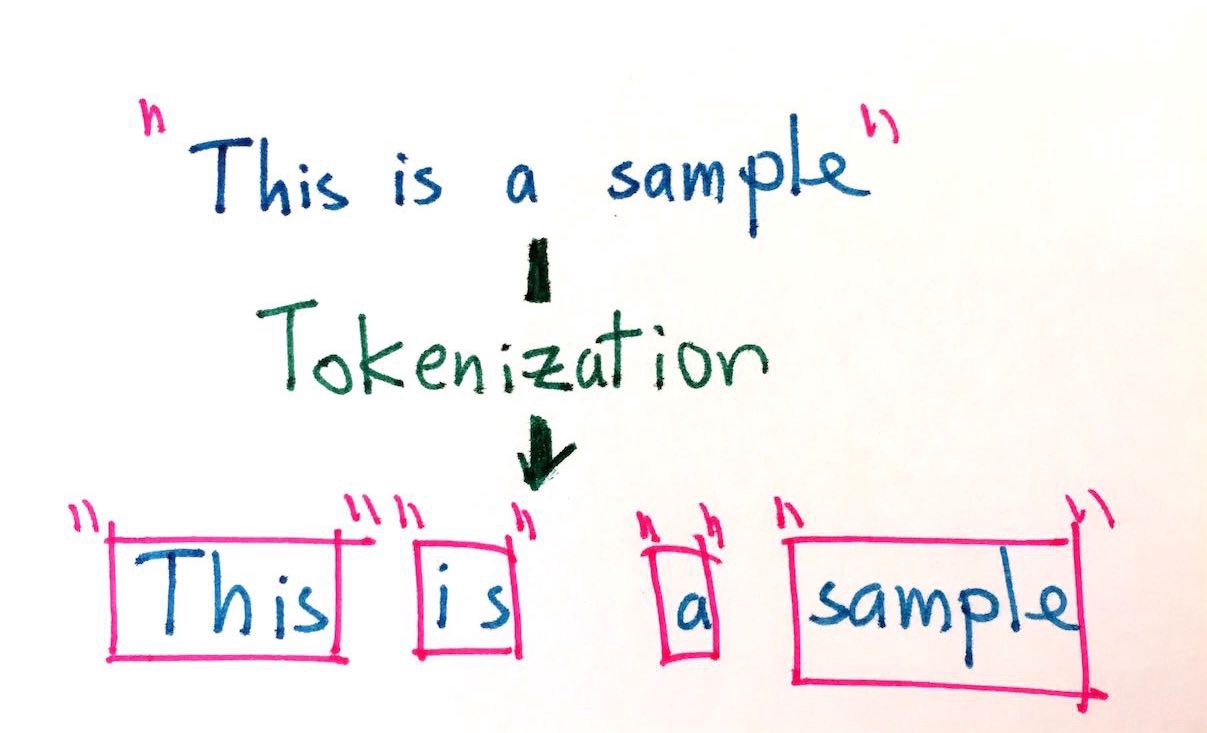
This article will walk you through an important concept in NLP, that is Tokenization and different methods and types of tokenizers used.
But first, let us do a very simple exercise to understand why is reading difficult for machines and why is Language Processing a relatively difficult task. Consider the following question:
Computers are really interesting. What do you think about it?
You can write your answer in the text field below. You can just answer 'Yes' or 'No' or can write a complete essay on it (or simply skip it. It won't make a difference though). Let us see if you are able to answer it.
So, did you make it? I am pretty sure you did. Was it easy? Yes. It was very easy. But, why was it easy? How were you able to understand what I asked and what do you need to write?
This is because we have an ability to understand language easily. For example, you could understand what your teacher wanted to teach you in kindergarten even before you learned to write or read. This is because we have an ability to understand phonetics, or sounds in layman's terms. This phonetic ability gives us an upper hand from the computers.
Moreover, there are a couple of more questions to be answered here. If you take a closer look at the question, The question which I asked was What do you think about it?. Right? So, how did you know what was being asked about? This is another ability a computer does not have by default, that is the ability to interpret context. This makes it difficult for computers to "read".
Why is tokenizing required?
So it seems to be clear that it is difficult for computers to "read". So, to make machines read the text, there are two methods which we can employ. One way is to give all the words (and their different combinations) of the language to the computer explicitly, which will create a static database and then we can create a set of lookup rules to get the required words from the dataset in the required order. This is a very naive approach and is certainly not feasible. Another way of leveraging this is to somehow make the computer recognise the text while reading. So, the more it reads, the more it learns to understand the words. Humans do this using the phonetic capability. But as machines do not have this capability, a system called Tokenization is used. Tokenization is a process in which the text is broken into smaller parts and fed to the machine for further processing.
To train Deep Learning models like BERT, GPT-2, or any other variants of the Transformers (we will look into these models in detail in further posts), we need to feed a lot of text into them. According to the architecture of these models, they are designed to capture the syntactic and semantic information from the text and use the learnt information to perform various language specific tasks. Now, each of these models are designed in different ways. For instance, the GPT architecture has a stack of decoder layers while the BERT architecture has a stack of encoder layers. On the other hand, Transformers have units of both decoder as well as encoder. So, regardless of their design, there will be an input layer which will feed the text to the particular model. Thus, we need the text input to be generalised.
A naive approach will be to feed the whole text as it is to the model. But a drawback is that we need to find a way to represent the text in numbers. Moreover, we also need to do this in such a way that the model, whichever it might be, should be able to "understand" the language. In other words, it should be able to understand where a word starts and ends, where a sentence starts and ends. So it will be complete non-sense for the machine. Thus, the following two things need to be done:
- Split the text into smaller parts. This will help the machine with the second problem above. Moreover, it will also give a specific consistency to the text. And it will be now easier to group the text based on this chunks.
- Represent each chunk as a vector. This will help us deal with the first problem above. As machines are unale to process anything other than numbers, it will be a great way to give the text as an input. This may raise a question as to why do we need to epresent the words as vectors? One can simply assign unique numbers to each tokens. This will save a lot of space. The answer to this is that if we encode the tokens with vectors, we will be able to even represent the relationship between two tokens with the vectors. This will be very helpful for the model than just giving out simple numbers to it. Hence, vectors are a preferred choice over scalars.
This leads us to the question that how should we split the text into chunks? We will discuss two different ways to do this and the drawbacks of each method.
- Splitting based on words
- Splitting based on characters
1. Splitting Based on Words:
This method is the most intuitive method of tokenization. Most of us agree that this is the best approach of tokenization. And it is undoubtedly a good option. But, some of the demerits and difficulties are:
- Different tokenization forms for a single sentence: Consider the sentence- "This doesn't seem right". Now, if we want to tokenize this sentence, there can be multiple possible ways:
- <This> <does> <n't> <seem> <right>
- <This> <doesn> <'t> <seem> <right>
- <This> <doesn't> <seem> <right>
- Running out of Vocabulary: Personally, this is the most faced problem while tokenizing the text. When we tokenize the text on the basis of words, we learn only the words which are present in the training text. In case of a new word encounter, we can not transform it to the vector form as we have not seen the word ever before. To tackle this problem, a special token named Unknown Token is usually introduced in place where an unknown word is encountered. The Unknown Token (generally denoted as <UNK> by most of the tokenizers) is provided with a vector and all the unknown words are assigned this vector. This will create a requirement of having a training set consisting of a large vocabulary. If the train dataset does not have a considerable vocabulary, the model will learn less words and will have more number of Unknown Tokens as input due to which the model will not be able to generalise as expected. Thus, this approach makes it imperative for us to have a large vocabulary.
- Agglutinative Languages: This is a common problem in many of the languages. Let us take an example of Indian Languages, for instance, Hindi or Gujarati. These languages have a typical scripting structure. They have the ability to represent several words as a single word. For instance, the phrase "In the memory of" has four words in total and will give four tokens if tokenized based on the number of words. But, the same phrase translates to "સ્મર્ણાર્થે" in Gujarati and "स्मर्णार्थ" in Hindi which tokenized using the word rule will give only a single token. The languages having this property of representing multiple words joined as a single word are called Agglutinative Languages. The tokenizer for these languages should be able to separate out the independent root words successfully which the simple tokenizer like this can not accomplish. This combination is also a problem in languages like English which have combinations of words like stand-up, check-in, etc
- Abbreviations: This is a common problem in Modern English language. With the evolution f English Language, we have a lot of abbreviations like IMHO, IDK, and so on.
2. Splitting based on Characters:
Instead of tokenizing the text based on words, this method tokenizes the text based on the characters. By this method, some of the downsides of the word based tokenization can be normalized. This method can be illustrated as belows:
Consider the phrase- "Tokenizin' this". Based on the character level tokenizing method, this will generate the following output:
This method seems to tackle some of the limitations of word level tokenizing. now, we do not need to worry about running out of vocabulary. As any word/sentence can be formed using the character level embeddings generated from these tokens. So, we will be able to tackle the Unknown Token problem. Moreover, we can aso tackle the agglutination and abbreviation problem.
Another potential advantage of this method is that, it may be possible that it can also tackle the problem of mis-spelled words or words like coooool or heyyyaa. Possibly, the character level tokenizer will learn the embeddings of the character in such a way that the mis-spelled words like this generate the same vectors as the original words. The same can be the case of words and its root form, like walk-ed and walk and walk-s may learn the same embeddings or embeddings which have very less distance between them.
Inspite of the many advantages, here also, we face a disadvantage similar to the word level tokenization, that is the problem of more than one representations for the character level tokenization as well. For instance, the above tokenization can also be represented as:
which has ignored the punctuations, or
which adds a special token / to represent space
The character level tokens will require some pooling before being fed into the model. Pooling, in simple words, is just a downsampling method which can reduce the dimensions of the vector by various methods like averaging or taking the maximum. More information can be found in this kaggle answer
Some more disadvantages of this method are:
- Lack of Meaning: As the word level tokenizer tokenizes based on words, the meaning of the text is somewhat retained in the tokens. On the other hand, the character level tokens may fail to retain any meaning as letters may be combined in any pattern which may not be even correct words.
- More Computation requirements: This method will also increase the requirement of computational resources as the number of tokens will increase and hence require much more storage space and computation time.
- Limited model choice: Some of the sequence based models like RNN process the inputs sequentially. This makes the model architecture highly dependent on the length of the sequence. More sequence length will make the sequencial model to forget the far initial sequence when the length of the sequence is large. And as we will have a larger sequence here due to large number of tokens, this may not be suitable for such models. But, this method can turn out to be suitable for sequence independent models like BERT where the whole sequence is processed parallely.
These were some methods of tokenizing a text and representing them in the form of machine readable vectors. To check the length of this article, I shall write a different article on the methods of Tokenization like Subword Tokenization, Byte Pair Encoding and N-Gram Subwords Tokenization in detail. Please let me know your feedback regarding this article and if you liked the article, please share it using the links provided below. Also, do suggest me about any improvements which I may implement to make the blog even better. Further, I will be writing about various Machine Learning algorithms in future posts. Please stay tuned! Until then, have a great time!