Positional Embeddings
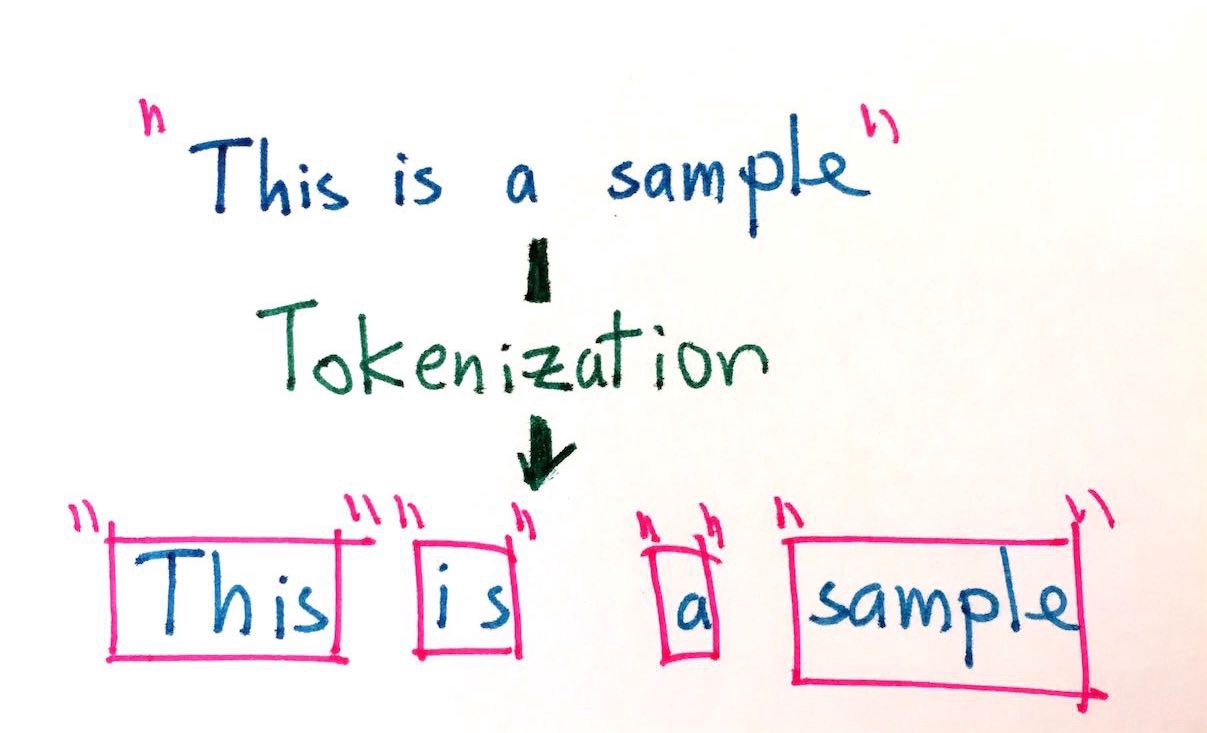
The Transformers architecture was proposed as a purely attention based sequence to sequence model. Due to its ability of processing the text parallely and its advantage of solving the long sequence dependency problem of RNNs, this architecture has become very popular among researchers for performance improvements. This article discusses about a special part of the architecture, which is the Positional Embeddings.
Continue Reading